Zur Funktion des propriozeptiven Sinns
Heinrich von Kleist, Unwahrscheinliche Wahrhaftigkeiten mit Sonagrammen – Teil a
von Helmut Becker
Erschienen in: Recherchen 177: Die Leiblichkeit der Texte (04/2026)
[...] Überprüfen wir nun, ob die muskulär-gestische Vorbereitung tatsächlich Auswirkungen auf den Sprechklang hat. Wenden wir uns sprechend – dabei in Vorbereitung auf den Sprechakt die vier verschiedenen Vorstellungen aktivierend – der entsprechenden Textpassage zu, die bei der ersten Lektüre noch relativ unkonkret geblieben war, nach dem Umrechnungsvorgang aber an Konkretion gewonnen hat:
Ein ungeheurer, mehrere tausend Kubikfuß messender Block
Um eine Vergleichbarkeit der verschiedenen Varianten zu gewährleisten, werden diese mit einem leistungsstarken Mikrofon aufgenommen. Die entstandenen Klangbeispiele werden anschließend spektral analysiert, um mittels der entstehenden Diagramme objektive akustische Werte ablesen zu können.
In einem ersten Durchgang wird die Wortgruppe zunächst ganz ohne muskulären Mitvollzug, aber durchaus strukturiert, mit Tempovariation und klaren (sparsam gesetzten) Schwerpunkten geäußert: eben wie ein geübter Nachrichtensprecher sie sprechen würde. Da gute Nachrichtensprecher und Sprecherinnen sich innerlich durchaus auf die Objekte und Sachverhalte beziehen, von denen sie berichten, entspräche diesem ersten Durchgang wohl das Sich-vor-Augen-stellen des Felsblocks. Es entsteht auf diese Weise eine intelligente, gut informierende Sprechversion.
🔊6.1.4.a. Die folgenden drei Varianten (sachlich, von innen ausmessen, umfassen) wurden hintereinander aufgenommen.
Für einen weiteren Sprechversuch könnte man sich, wie oben beschrieben, mit ausgebreiteten Armen in die Hohlform des Blocks hineinbegeben, um auf diese Weise sein Volumen auszumessen.
In einem dritten Versuch würde man den Felsblock zu umfassen versuchen. Der raumgreifende Bewegungsgestus der Versionen zwei und drei führt jeweils zu einer Weitung und Aufrichtung des Brustkorbs, einer Tieferstellung des Zwerchfells und damit zu einer Öffnung des Vokaltrakts.
Abschließend wird versucht, den imaginären Felsblock anzuheben: Einmal mit stimmlicher Anstrengung, ein andermal mit entsprechender körperlicher Vorbereitung, welche die Stimme freilässt. Hierbei ist bemerkenswert, dass beim Abhören der Tonaufnahmen der stimmliche Eindruck der Varianten des Umfassens und des (vorbereiteten) Anhebens kaum zu unterscheiden war. Es wird deshalb für die Analyse beider Varianten auf eine stimmliche Version zurückgegriffen. Berücksichtigt wurde allerdings die aufschlussreiche vierte, mit Anstrengung gesprochene Variante.
🔊6.1.4.b.
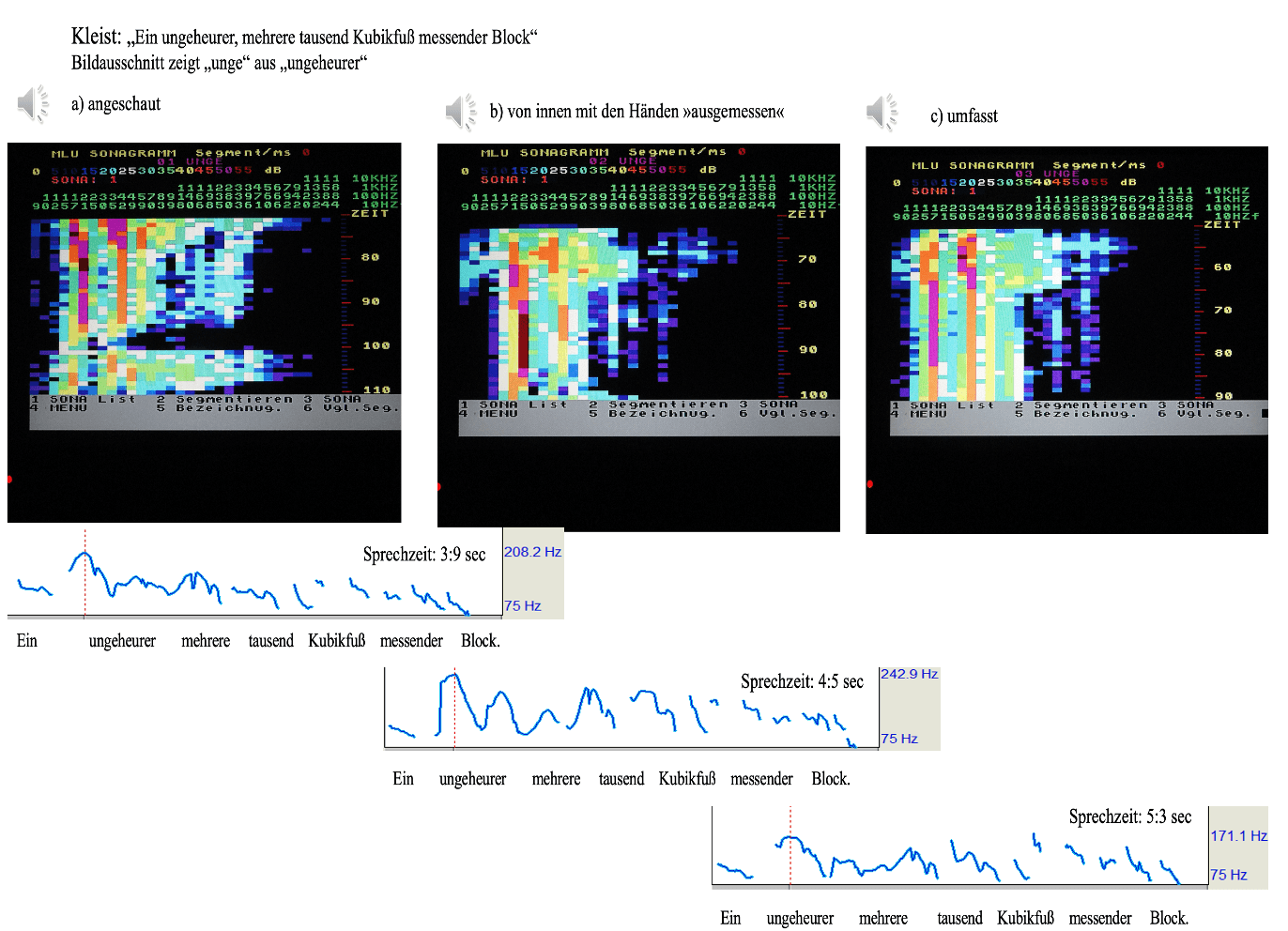
Sprechvarianten und Sonagramme
Der unterschiedliche Stimmklang der vier Varianten resultiert (neben der Tempovariation) aus einer unterschiedlichen Belegung der Frequenzen des Stimmspektrums. Er lässt sich grafisch sichtbar machen: in Form von »Sonagrammen«, die den Zeitverlauf der Äußerungen spektral (also über das Frequenzspektrum) abbilden.
Zu den unten abgebildeten Sonagrammen einige Anmerkungen: Die fließend gesprochene Sprache wurde spektral analysiert, und zwar mittels einer 32-Kanal-Filterbank mit einem Erfassungsbereich von 90 Hz bis 18840 Hz.[1] Die Sonagramme differenzieren das Untersuchungsergebnis nach drei Dimensionen:
• Auf der x-Achse (also von oben nach unten!) wird der zeitliche Verlauf abgetragen.
• Auf der y-Achse werden die zugeordneten Frequenzbereiche sichtbar.
• Die farbliche Abstufung kennzeichnet den Schalldruck, d.h. die unterschiedliche Lautstärke der einzelnen Frequenzbereiche.
Beschreibung des Sonagrammbilds:
• in Zeile 2 ist der untersuchte Sprachausschnitt angegeben. In unserem Fall: die zwei Silben »unge«.
• Zeile 3 zeigt die farblich differenzierte Abstufung des Dynamikbereichs in dB (Dezibel) an. Sie verläuft, dies ist anzumerken, nicht ganz intuitiv, was die Farbauswahl betrifft. So werden die schwächsten Frequenzen mit kräftigem lila (10 dB), dunkelblau (15 dB) und hellblau (20 dB) abgebildet, weiß dargestellte Frequenzen (25 dB) liegen im mittleren Bereich, das Grünspektrum belegt den Bereich zwischen 30 und 35 dB; schließlich steigert sich der Schalldruck im oberen Dezibel-Segment von gelb (40 dB) bis dunkelrot (55 dB).
• Zeile 5-7 zeigt die Frequenzskala. Die angegebenen Werte sind von oben nach unten zu lesen und müssen mit dem Faktor 10 multipliziert werden. 25 entspricht also 250 Hz.
Jedes Farbkästchen bildet einen Messpunkt ab: zu einer bestimmten Zeit, mit einer bestimmten Frequenz, mit einer bestimmten Lautstärke. In der Gesamtheit der Farbsegmente wird die Klangfarbe (das »Timbre«) der jeweiligen Sprachvariante optisch lesbar. Sie resultiert aus der Grundfrequenz und der Lautstärkeverteilung/Energieverteilung in den einzelnen darüber liegenden Frequenzbereichen.
Der genaueren Lesbarkeit des Sonagramms wegen wurden aus der gesamten Äußerung »ein ungeheurer, mehrere tausend Kubikfuß messender Block« lediglich zwei Silben analysiert: die Anfangssilben [´ʊngɘ]. Diese beiden Silben wurden in einem Abstand von 6 Millisekunden (6ms) gemessen. An ihrer spektralen Ausprägung lässt sich das jeweilige stimmliche Engagement des Sprechers ablesen.
Bei einem ersten vergleichenden Blick auf die Sonagramme fällt auf, dass der Höreindruck der drei ersten Varianten (anschauen / sich in den Block hineinstellen / den Block umfassen) deutlichere Unterschiede aufweist als ihre spektralen Abbilder. In allen drei Varianten zeigen sich ausgeprägte Frequenzbänder: Abbild einer »Sonorität«, d.h. eines großen Resonanzreichtums, der allerdings im vierten Schaubild (der stimmlich angestrengten Variante) völlig wegfällt.
Zunächst gilt es einem Missverständnis vorzubeugen: In der ersten Version (»anschauen«) taucht zwischen den beiden Silben [ʊn] und [gɘ] im Frequenzbereich oberhalb 350 Hz ein deutlicher Spalt (schwarz gefärbt) auf. Dass dieser Spalt in den Versionen b) und c) nicht mehr zu sehen ist, liegt allerdings nicht an der resonatorischen Brillanz dieser Versionen, sondern schlicht daran, dass beide Silben hier mehr Zeit in Anspruch nahmen. Damit wurde die zeitliche Kapazität dieser Aufzeichnungsvariante, die bei 240 Millisekunden liegt, schlicht überschritten. Das bedeutet: Ein entsprechender Spalt wäre auch in den Versionen zwei und drei aufgetaucht, trat aber nicht mehr ins Bild. In diesen Varianten ist daher nur die Silbe [ʊn] spektral abgebildet. Die drei Varianten dieser Silbe [ʊn] sollen im Folgenden miteinander verglichen werden. Das bedeutet: auch im ersten Schaubild ist nur der Verlauf der ersten Silbe, also der Abschnitt von oben bis zur schwarzen Lücke zu berücksichtigen.
Auch ein zweites Hinschauen führt eher zur Erkenntnis, dass alle drei Versionen sich durch ähnlich markante Frequenzbänder auszeichnen, die dem Energiereichtum aller drei aufgesprochenen Varianten entsprechen: Zu sehen ist in allen drei Fällen (von links nach rechts gelesen) in gelb-roter, energiereicher Ausprägung der Grundton und der erste Formant.[2]
In Andeutung erscheint beim ersten Diagramm in rotgelber, bei den Diagrammen 2 und 3 in gelb-grüner Ausprägung ein drittes Frequenzband (bei dem nicht ganz klar ist, wie es zu bezeichnen ist).
Dennoch ist nicht wegzudiskutieren, dass der Höreindruck der dritten Variante deutlich »voluminöser« und »gewichtiger« erscheint als in den Varianten 1 und 2.
Beim dritten Hinblicken fällt endlich auf: Die Frequenzbänder sind in den drei Varianten zwar ähnlich markant ausgeprägt; sie sind jedoch im Spektrum ganz unterschiedlich platziert! Grundton a) liegt bei 210 Hz, Grundton b) um die 250 Hz, Grundton c) bei 170 Hz. Dies entspricht auch den gemessenen, unter dem Diagramm notierten Frequenzen für die Silbe [ʊn].
Wenn im Folgenden bei den drei Varianten auch die Frequenzen des ersten und zweiten Formanten differieren, so ist dies nicht (obwohl es ja naheläge) mit den unterschiedlichen Grundtonfrequenzen der Beispiele zu begründen. Die Position der Formanten ist, wie in der Fußnote erwähnt, grundsätzlich grundtonunabhängig! Sie differiert allerdings in Abhängigkeit von der Klangfarbe der Vokale.[3] Hören wir uns die Klangbeispiele nochmals an, so erscheint die Korrelation zwischen Lage der Formanten und Klangfarbe durchaus stimmig:
Der weder ausgeprägt hell noch dunkel erscheinenden Sonorität von Beispiel a) entspricht die Platzierung des ersten Formanten bei 420 Hz; ein weiteres energiereiches Frequenzband ist bei 590 Hz erkennbar; auf der Suche nach einem deutlich erkennbaren 2.Formanten (in der Region zwischen 700 und 100 Hz) werden wir nicht fündig, wohl aber weiter oben bei den Werten 1660 Hz und 2800 Hz. Dass in dieser Höhe noch klar erkennbare Frequenzbänder zu finden sind, erklärt die Klangfülle des ersten Klangbeispiels.
Mit der deutlich »helleren« Version b) steigt der erste Formant bis auf 490 Hz an; der zweite Formant steigt auf 1160 Hz an. Damit korrespondiert die sonore Helligkeit des Klangs.
Die stimmlich »dunklere« Version c) lässt den ersten Formanten auf 350 Hz sinken. Zwei ausgeprägte energetische Frequenzbänder um 490 und 700 Hz (dies wahrscheinlich der 2. Formant) komplettieren den energetischen Eindruck der Fülle. Damit wird nun endlich ein klarer Unterschied zwischen den einzelnen Schaubildern erkennbar. Und es lässt sich eine Korrelation im Schaubild zum »Gewicht« des Klangbeispiels c) finden: Die »Gegründetheit« der dritten Variante verdankt sich nicht nur der tieferen Grundfrequenz, sondern auch der (im Vergleich zu den Varianten 1 und 2) tieferen Position des ersten und zweiten Formanten.
Ein weiteres Element kommt hinzu. Die unterschiedliche Zeitdauer der einzelnen Varianten spiegelt sich auch in der Dauer der Silbe [ʊn]. Liegt diese in der Chronistenfassung (Beispiel 1) bei ca. 25 ms (abzulesen an der Zeitskala rechts), so liegt sie in der ausmessenden Variante (Beispiel 2) bei mindestens 36 ms (unklar bleibt, wo die Silbe am unteren Ende des Diagramms genau endet), in der umfassenden Variante bei mindestens 40 ms. Ist die unterschiedliche Silbendauer durch den Vergleich der Schaubilder einmal dingfest gemacht, so wird sie auch beim darauffolgenden nochmaligen Abhören der Versionen unüberhörbar. Erfahrbar wird: die längere Zeitdauer der tieffrequenten, »dunklen« Silbe [ʊn] in der dritten Variante imponiert einerseits als besondere Nachdrücklichkeit, als ein Verweilen in der »umfassenden« Auseinandersetzung mit dem Felsblock; andererseits kann sie auch als »Ausdehnungserfahrung« gehört werden
Die hörbare akustische »Räumlichkeit« der zweiten Variante (»sich hineinstellen«), die sich akustisch vor allem aus dem Tonhöhenintervall zwischen 75 Hz und 243 Hz ergibt, kann selbstverständlich in der spektralen Messung einer Silbe nicht abgebildet werden. Im Diagramm zeigt sich (von oben nach unten) zumindest die deutliche Längung der Silbe [ʊn], welche wie in Version drei den Ausdehnungscharakter des benannten Objekts unterstützt.
Um sich in die vierte Version, das Anheben, hineinversetzen zu können, kann man sich versuchsweise ganz real an einem schweren Gegenstand abarbeiten: Man versucht (mit allem gebotenen Respekt vor dem Gewicht des Objekts) z. B. eine Waschmaschine anzuheben. Direkt darauffolgend versucht man, die sinnlich erlebte Kraftanstrengung in der »muskulären Imagination« wieder aufzurufen. Wer ein solches Anheben während des Sprechvorgangs einmal tatsächlich durchführt, wird bemerken, dass er zwischen zwei Optionen wählen kann. Entweder er entscheidet sich dafür, die muskuläre Anstrengung unmittelbar auf das Stimmorgan einwirken zu lassen. In der Folge wird sich der Atemdruck auf das Stimmorgan hörbar erhöhen, der Vokaltrakt wird sich verengen, die Stimme wird ebenfalls eng und leicht überhöht klingen.
🔊6.1.4.b.
Wer sich aber mit dem Sprechen Zeit lässt, bis Muskulatur und Atmung sich auf den zu bewegenden Gegenstand eingestellt haben, der wird deutliche Auswirkungen auf Atem und Stimme bemerken. Mit der Erhöhung der gesamtkörperlichen Muskelspannung ist in diesem Fall eine Intensivierung der Beckenbodenspannung ebenso wie der Stimmlippenspannung verbunden. Der Atem vertieft sich merklich in Richtung Beckenboden, er weitet sich von innen in der Körpermitte, während sich gleichzeitig die gesamte Rumpfmuskulatur auf den Hebevorgang einstellt. Die Stimme setzt tiefer und deutlich voller ein, die Artikulationsspannung intensiviert sich.[4] Die Resonanz der stimmhaften Konsonanten ist hörbar verstärkt, bei gleichzeitiger Längung der Silben [ʊn].
Da das akustische Erscheinungsbild des »Umfassens« und des »Anhebens mit Vorbereitung« nicht wesentlich voneinander abwichen, wurde auf eine optische Erfassung der letzteren Variante verzichtet. Um sich einen akustischen Eindruck des »Anhebens mit Vorbereitung« zu verschaffen, kann daher auf die Variante drei (»umfassen«) zurückgegriffen werden.
[1] Die Tonaufnahmen für den Kleist-Text und den weiter unten analysierten »Bakchen«-Text wurden am 17.7.2024 im Tonstudio der Bayerischen Theaterakademie vorgenommen, unter der Aufnahmeleitung von Tonmeister Udo Terlisten und meinem Kollegen, Prof. Dr. Uwe Hollmach. Benutzt wurde ein leistungsfähiges Neumann-Kondensator-Mikrofon. Uwe Hollmach konzipierte und baute die erwähnte 32-Kanal-Filterbank und war maßgeblich an der spektralen Auswertung der Tonaufnahmen beteiligt.
[2] Als Formanten werden innerhalb des Klangspektrums Frequenzbänder bezeichnet, in denen sich die akustische Energie verdichtet. Die Lage der Formanten ist nicht vom Grundton abhängig, sondern ist (bei der menschlichen Stimme) mit einer relativen Konstanz einzelnen Vokalen zugeordnet.
[3] Die Vokal-Formanten von Kinder- und Frauenstimmen liegen leicht höher als die der Männerstimmen.














")

